

Chrome 90 Bug Causes Incorrect Download April 26, 2021
The Chrome browser has been flirting with the idea of cache partitioning for some time. But this experimental feature somehow sneaked in with the recent release of Chrome 90, in the form of a bug. Well, technically two bugs. We'll get to that soon.
Normally, when a web page displays an image, or an embedded PDF document, the content of the image or document can be saved as files. And the saved files should contain the exact same content as is being displayed in the browser. Apparently this is no longer the case with Chrome 90. One plus one no longer gives you two!
To trigger this bug, some conditions must be met:
- the static content (image, PDF, audio) must be embedded in an iframe
- the hosting domain has a service_worker to fetch cached files
It is extremely easy to meet these conditions. iframe is widely used to embed content and to create an isolated browsing context for security reasons. It is used in many document viewers and rich text editors.
The use of a service worker is also widespread. The mere presence of a service worker, however, seems to confuse Chrome 90, even though the worker is simply fetching cached files.
We built a proof of concept - a simple web page that loads an image in an iframe. The image is dynamically generated so that the caching issue can be easily exposed.
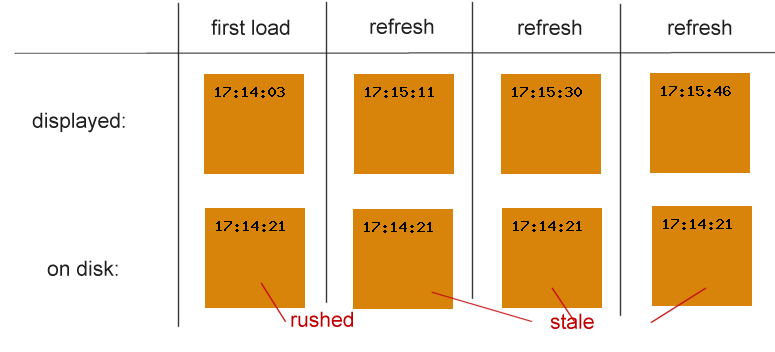
When the image is loaded for the first time, we save the image and open it in an image viewer. The saved image already shows a different content - a time that's "in to the future". Subsequent refreshing of the page displays fresh versions of the image. But if the image is saved, the browser stores the initially downloaded content.
You can check out the live demo here.
To an end user of a web product, this bug creates annoyance on the light side, and in more serious cases, legal complications. The files (PDF reports, Word and Excel documents, media files) people download are often worth downloading. Some of them may be contractual in nature. If what one sees is not necessarily what one stores, a fundamental trust is broken.
To web developers and maintainer of web products, this bug could cause major support issues. First, the downloaded content is mysteriously wrong, and this in itself would drain much diagnostic resource. Then, more effort must be spent on explaining and educating the end users.
So how does one fix this issue? In Chrome, enter chrome://flags in the address bar. Then search "HTTP Cache Partitioning". You'll see a screen like this:
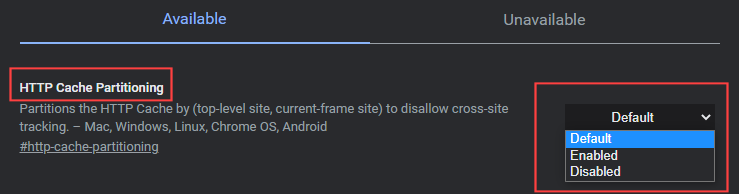
Although HTTP Cache Partitioning is considered an "experimental feature", the default setting seems to be "Enabled". This is the first of the two bugs.
Once we set Cache Partitioning to Disabled, the problem should go away.
But let's leave it Enabled for now, so that we can unearth the other bug. Since we don't have the time to comb through the Chromium codebase, we can speculate this bug from outside observations.
Remember when the image was loaded for the first time, the clock showed 17:14:03. But the downloaded file showed 17:14:21 because the download was initiated 18 seconds later. It's evident that the download did not use any cached content, or that the displaying of the content didn't save to the same cache.
Subsequent download retrieved the same content. This shows that upon a cache-miss, the downloader populated a cache that is not touched by the renderer cache.
The Chrome team can argue in great lengths why, due to some intricate cache key and zoning design, that this is the "correct" behavior. However, one thing that's certain - the enforcement of the cache rules should not be split between Display and Storage, no matter how the cache is, "partitioned". If there was a good reason (which, really, there isn't) to freeze the cache in the iframe so that every downloaded file is stale, then the viewing content should also be stale. Conversely, if every page refresh gives a renewed content, then the user should be saving what they see.